
Exploration and Exploitation in Active Learning
Many machine learning algorithms require a plethora of labeled data in order to be accurate in practice. For example, most deep learning neural network architectures requires many input and output pairings in order to properly adjust model parameters to accurately reflect the training data and hopefully generalize to testing data. However, labeled data in the real world is often difficult to acquire; e.g. properly labeling (i.e. classifying) images of lung Xrays requires expert supervision that is costly both in time and money. While it is relatively easy to obtain a large amount of inputs (e.g. lung Xrays), it is costly to accurately obtain a sufficient amount of outputs (labels) from human labeling efforts (e.g. doctor hand classifying the lung Xrays).
Active learning seeks to alleviate this problem by selecting “important” inputs to use your limited resources for human labeling. While there are different active learning paradigms, my research focuses on pool-based active learning, wherein our active learner has access to a “pool” (database) of inputs X from which it can select a subset Q which we will ask the human (oracle) to label. These labelings are fed into our underlying machine learning classifier, wherein we update the classifier (model retraining) and then select another subset of query points. The underlying machine learning classifiers that I work with are graph-based semi-supervised learning methods that leverage the geometric relationships between the labeled and unlabeled inputs via the use of a similarity graph in order to infer the labeling information on the unlabeled inputs.
The main question for us in this active learning paradigm is how to select that subset Q of query points? In general, we want to select points that will be beneficial for our resulting underlying machine learning classifier. To make this a bit more precise, there are two properties of our active learning query choices that we would like to balance:
- Exploration : We want to properly “explore” the inherent geometric/clustering structure of our dataset’s inputs. These points will be representative of our input data.
- Exploitation : We want to adequately “exploit” the classification structure that we have learned from our previously observed labeled data. These points will be informative for refining the decision boundary between our classes.
Generally, active learning methods favor one or the other of these properties. I want to create methods that naturally combine and balance the desiderata of exploration and exploitation.
Demo Visualization
As a toy example, consider the following “Checkerboard 3” dataset, whose ground truth labeling is shown below in Figure 1. This dataset is comprised of 3,000 point sampled uniformly at random from the unit square. The classification of the points in the dataset are determined via the 3 x 3 grid structure shown in the figure of the ground truth. Representative points would lie in the interior of the respective squares while informative points would lie on the decision boundary of the current classifier. A “good” active learner will generally first explore the clustering structure and then exploit the learned decision boundary information.
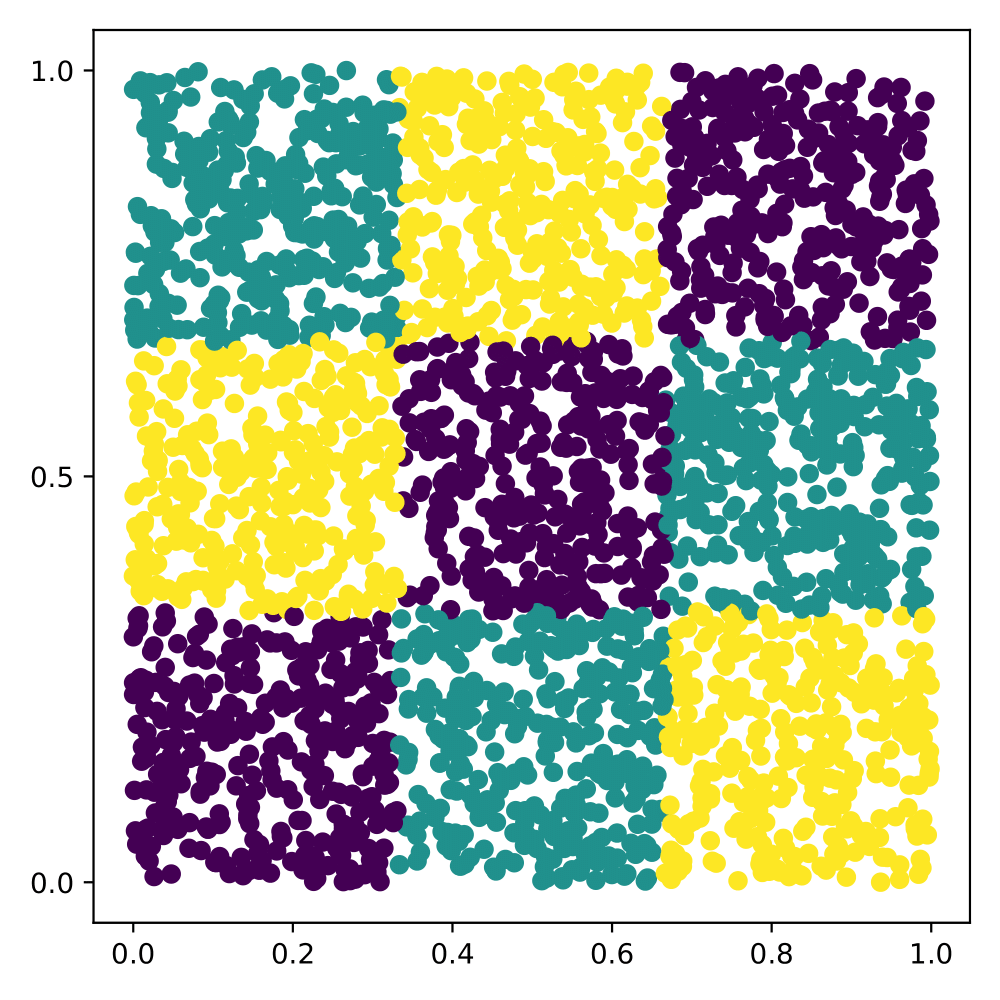
The following animation shows the active learning process using my graph-based model change acquisition function; the left panel shows the current classifier’s classification given the current labeled data, while the right panel shows a heatmap of the acquisition function. In the heatmap, lighter colors correspond to higher acquisition function value (i.e. more “valuable” points to label).
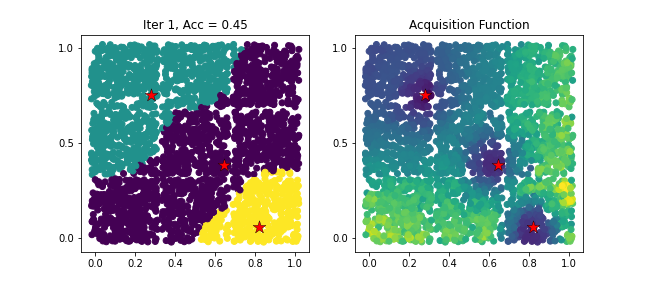
Notice that early on in the iterations, when we have limited labeled data, the criterion explores the extent of the data domain (i.e. queries points in unexplored regions of the unit square). Then, after a few iterations, the criterion focuses on the the boundaries between squares of different classes; i.e. exploits the observed labeled data when there is enough information about the extent of the data domain.
Takeaways
While this toy dataset is not realistic, I think the visual provides a useful demonstration for gaining intuition about the balance between exploration and exploitation. The principles displayed here generalize to real-world and empirical datasets: we must first explore the extent of the clustering structure and data domain and then exploit the current information for refining the classifier’s decision boundaries. Many active learning criterion do not naturally transition automatically like how the presented model change acquisition function here does. I want to continue to explore ways in which we can use this model change acquisition function in other semi-supervised learning models besides the simple graph-based models I have previously analyzed.